Introducing Bighammer's AI-Powered NLP Pipeline Agent from Plain English to Production-Ready Data Pipelines
We've been building something at Bighammer that we believe is a genuine step-change in how data engineering teams build ETL/ELT pipelines and we want to share the thinking behind it.
The Problem We Were Solving
Building a data pipeline has always been expensive in the wrong ways. You spend weeks (sometimes months) on requirements gathering, source-to-target mapping documents, code reviews, test data creation, and environment setup, before a single byte of real data flows. And even then, the output is tightly coupled to one cloud provider or compute engine, making migrations brutal.
We asked ourselves: What if an AI agent could do most of that work end-to-end, using your own business language?
Why Most "AI Pipeline Generators" Fail
LLMs are powerful, but they hallucinate. Ask a general-purpose AI to generate a production data pipeline and you'll get something that looks right but:
- Maps the wrong source columns because names seemed similar
- Invents transformation logic that doesn't match the actual business rule
- Generates test data that doesn't cover real edge cases
- Produces code that only runs on one cloud or one engine
- Has no way to tell you what it was uncertain about
- Leaves no trace of why decisions were made, making audits and debugging a nightmare
We've seen this pattern play out. And we knew that throwing a smarter prompt at the problem wasn't the answer.
The real answer: Don't let the LLM freestyle.
What We Did Differently...Structure Built from Real Data Engineering Experience
Our team has spent years in the trenches building data pipelines across banking, retail, healthcare, and manufacturing, working alongside data engineers who do this day in, day out. We took everything we learnt about how experts actually think when they build a pipeline and encoded it into a pre-decided, deterministic workflow.
The LLM is not the architect here. The workflow is.
Here is how we protect against hallucination at every step:
🔒 The agent never guesses sources blindly: it queries the Catalog, reads profiling data, and uses semantic embeddings to score candidates. Multiple independent signals must agree before a mapping is accepted.
🔒 Confidence thresholds gate every decisionlow: confidence mappings never silently make it through. They are flagged and escalated to an SME with a specific, targeted question not a vague "please review."
🔒 Transformation types are classified, not assumed: the agent classifies what kind of transformation is needed before any code is written. This classification is validated against the mapping requirement, not left to the LLM's intuition.
🔒 The pipeline schema is validated, not trusted : after the LLM generates the pipeline, it is run through a structural validation loop. If it fails, the agent automatically attempts to correct it up to multiple rounds before surfacing a result.
🔒 Test scenarios come from the requirement, not the code: expected outputs are derived from what the business asked for, not from what the LLM happened to generate. This means the tests catch pipeline errors rather than rubber-stamping them.
🔒 BigHammer Language enforces correctness by design: because we generate into an abstract intermediate language with a defined schema, the LLM cannot produce syntactically invalid transformation chains. The schema itself acts as a guardrail.
Think of it like a senior data engineer sitting next to the LLM at every step checking its work, overriding it when it drifts, and only signing off when the evidence supports the decision.

Built-in Observability, Auditing & Lineage. Not an Afterthought
One of the things that separates Bighammer from "generate and hope" AI tools is that every action the agent takes is tracked, traced, and auditable from day one.
Observability Every node in the agent workflow emits structured, searchable logs not free-text console output. Every mapping decision, confidence score, candidate evaluation, transformation classification, and validation result is recorded with timing data. You can see exactly how long each stage took, where bottlenecks are, and how the agent is performing over time across all your pipelines.
Auditing Every decision the agent makes is traceable to its source. Which source column was chosen and why? What was the confidence score? Was an SME consulted? What did they say? Did the pipeline pass validation on the first attempt or require correction? All of this is captured and stored, giving your data governance and compliance teams a complete, verifiable audit trail not just of the pipeline, but of the reasoning behind it.
Data Lineage From the moment a pipeline is generated, column-level lineage is tracked end-to-end. You know exactly which source field feeds which target field, through which transformations, in which order. This lineage is stored in the Bighammer metadata layer and shared across agents meaning your data catalog, governance tools, and downstream consumers always have an up-to-date, accurate picture of where every piece of data came from and how it was transformed.
In regulated industries banking, healthcare, insurance this isn't a nice-to-have. It's a requirement. We built it in from the ground up, not bolted on later.
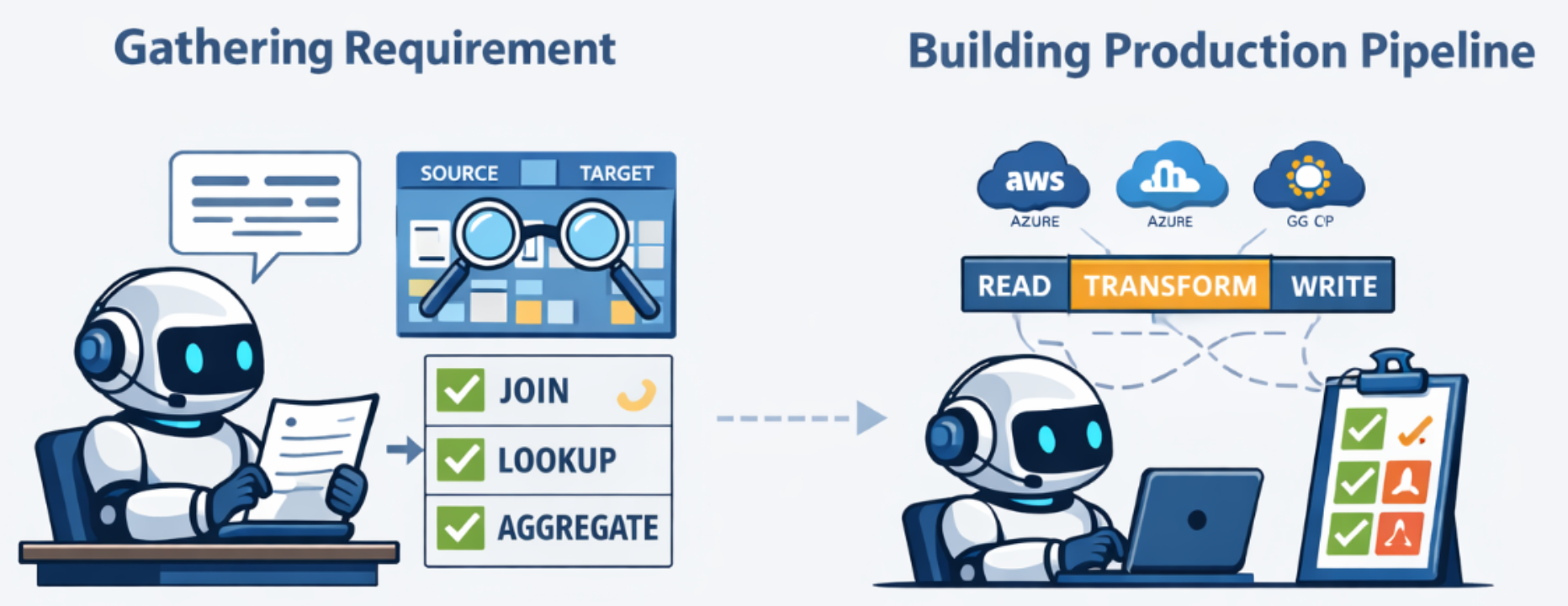
What the Bighammer NLP Pipeline Agent Does
Here's the full journey from a plain-English user requirement to a validated, cloud-agnostic, test-ready pipeline:
Step 1: Understand the Requirement You describe what you need in natural language. The agent reads it, reasons about it and starts working no special syntax required.
Step 2: Discover Sources & Targets from the Catalog The agent talks to the Bighammer Catalog your metadata layer containing schemas, data sources, glossary terms, domain classifications, and profiling statistics. It automatically identifies candidate source and target tables relevant to your requirement.
Step 3: Build Source-to-Target Mappings For every target table and field, the agent determines which source tables and columns are the right suppliers of data, including resolving cross-table relationships.
Step 4: Rank Source Candidates with Multi-Signal Scoring For each target field, the agent uses multiple independent signals catalog metadata, data profiling statistics, and semantic embeddings to score and rank every candidate source column. Think of it like a panel of expert reviewers independently voting, and the best answer emerging from their combined judgment.
A simple example: imagine a target field called customer_identifier. There might be columns named cust_id, client_no, and account_key across three source tables. The agent uses name similarity, data types, nullability stats from profiling, and semantic meaning from descriptions to decide which is most likely correct and flags anything it isn't sure about.
Step 5: Identify Transformation Types Is this a direct copy? A concatenation? A conditional lookup? An aggregation? The agent classifies the transformation needed for each field - direct, cleanse, calculation, unpivot, lookup, deduplication, and more - before any code is written.
Step 6: Plan, Review & Generate SME Queries The agent builds a logical plan and checks its own confidence. Where it finds gaps, ambiguous business rules, missing context, low-confidence mappings, it generates targeted SME questions rather than guessing. High-confidence mappings go straight to pipeline generation. Humans stay in the loop where it actually matters.
Step 7: Generate Test Scenarios from Requirements Test scenarios are derived from the original business requirement - not retrofitted after the fact. The agent creates structured input/expected-output datasets covering happy paths, edge cases, and boundary conditions. Testing is driven by intent, not implementation.
Step 8: Generate the Pipeline in BHL (BigHammer Language)
We don't generate Python, SQL, or Scala directly. We generate BHL (BigHammer Language) an abstract, cloud-independent pipeline definition. BHL describes what the pipeline should do (read, filter, join, transform, aggregate, write) without prescribing how any specific compute engine executes it.
BHL pipelines can be compiled and executed on:
- Azure Databricks (PySpark)
- AWS EMR
- GCP Dataproc
- Snowflake
- ...and more as we add engines
Your pipeline logic is defined once and runs anywhere. No vendor lock-in. No re-engineering when you migrate clouds. No rewriting when your architecture evolves.
Step 9: Automated Test Execution in the Playground Users can validate their pipeline in a sandbox environment — no separate compute required. Synthetic test data is injected, the pipeline runs, and results are checked against expected outputs automatically. This dramatically reduces the time between "pipeline generated" and "pipeline trusted."
Step 10: Shared Metadata Powers Every Agent The Catalog, Glossary, Domain, Lineage, and Audit layers aren't just inputs to this pipeline agent, they're a shared knowledge foundation across all Bighammer agents. Profiling data, semantic descriptions, domain classifications, and lineage are continuously enriched and reused. As the platform learns more about your data, every subsequent pipeline it builds gets smarter.
LLM-Agnostic by Design
The agent is plug-and-play with any major LLM provider OpenAI, Anthropic Claude, Azure OpenAI, and others. Your team isn't locked to a single AI vendor any more than you're locked to a single cloud. Swap the model, keep the workflow.
What This Means in Practice
Teams using the Bighammer NLP Pipeline Agent are seeing:
✅ Days instead of weeks - from requirement to a working pipeline draft
✅ Built-in validation - the agent checks its own output and self-corrects before delivery
✅ Full auditability - every mapping decision has a confidence score, a reason, and a traceable history
✅ Column-level lineage - always know where your data came from and how it was transformed
✅ End-to-end observability - structured logs and performance metrics at every stage of the workflow
✅ SME time focused where it counts - on genuine ambiguities, not on transcribing obvious mappings
✅ Cloud flexibility - write once, run anywhere via BHL
✅ Trust by design - structured workflow means you know why every decision was made, not just what was generated
#DataEngineering #AIAgents #ETL #DataPlatform #Bighammer #BHL #CloudAgnostic #LLM #DataCatalog #NLPPipeline #GenAI #DataLineage #DataGovernance #DataObservability #Databricks #Spark