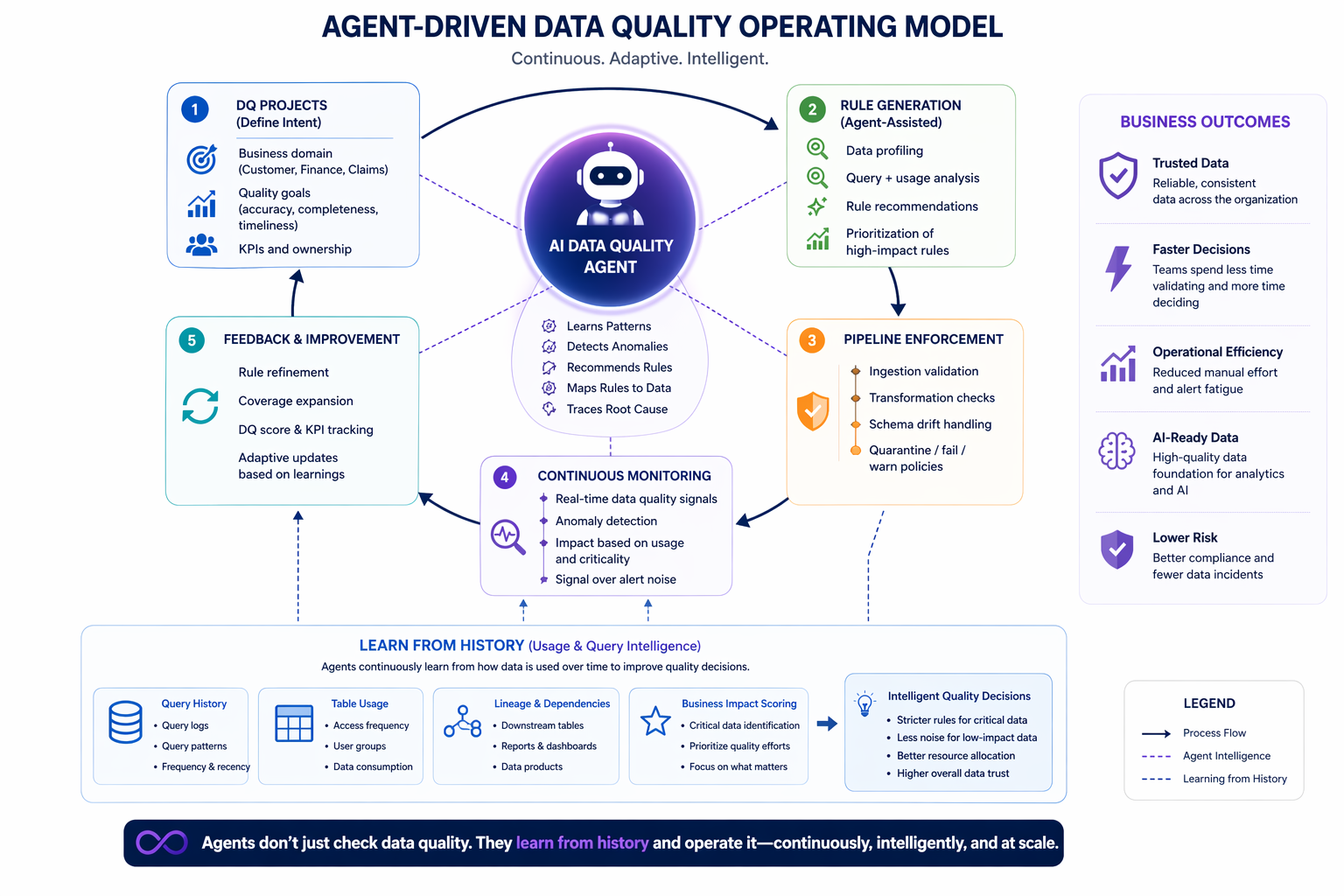
After decades leading data engineering teams at Fortune 500 companies, one thing is clear: the foundational problems haven’t disappeared — they’ve simply scaled with the explosion of data.
Recently, I’ve been fortunate to spend some quality time with my family and travel — a rare pause that gave me space to reflect on my work-related passions. It reminded me why I have stayed so committed to this field: data, transformation, modernization, and fostering a culture of innovation.
Across 20+ years in the IT industry, I have worn many hats — engineer, architect, change agent, and senior executive — helping organizations across the globe shape their data and analytics strategies, build hyperscale platforms, and execute large-scale cloud migrations.
Most recently, I spent four years at Dun & Bradstreet — one of the oldest data companies in the world — as Head of Data Platforms & Engineering. There, I led the modernization of a decades-old data supply chain that powers products used by majority of the Fortune 500. I oversaw the transformation of legacy scoring models used by global banks, built an exabyte-scale data & analytics platform, migrated critical workloads to the public cloud, decommissioned mainframes, and drove cost optimization through automation.
With GenAI now reshaping the tech landscape, the pace of change is accelerating. The businesses that will thrive are those that can move faster than their competition — adapting quickly, scaling intelligently, and embracing disruption.
This blog is a reflection on what I’ve seen across industries and roles: the same recurring pain points in data engineering persist — brittle pipelines, code-heavy processes, ambiguous ownership, high total cost of ownership (TCO), bloated tech stacks, and the myth of a “one-size-fits-all” platform. These issues continue to stifle agility and innovation. And unless we confront them head-on, we’ll keep wasting time, money, and talent.
I’ve decided to try and give back to the data engineering community that has supported me over the years and share my experiences for the good of the wider community.
Part 1: The Illusion of Progress
Despite billions spent and countless platform migrations, the core challenges in data engineering remain stubbornly familiar. GenAI promises a new era of automation and intelligence, but many organizations are still stuck in the same operational bottlenecks. We’ve traded legacy pain for modern complexity — but the symptoms haven’t changed.
The modern data stack — a constellation of tools like Snowflake, BigQuery, Databricks, dbt, Fivetran, Looker, and reverse ETL solutions — promised to simplify analytics. And to be fair, it did deliver some wins:
- ELT pipelines replaced brittle ETL jobs
- SQL-first frameworks like dbt made modeling more transparent
- BI tools introduced semantic layers for non-technical users
- Reverse ETL pushed insights back into operational systems
But here’s the uncomfortable truth: these are tactical improvements, not systemic fixes.
We’ve been promised agility, scalability, and democratization. Yet, most organizations still struggle to deliver timely, reliable data to their internal and external consumers.
- Data onboarding is still slow
- Data delivery is still fragile
- Replacing tools is still nearly impossible
Part 2: How We Got Here — A Legacy of Fragmentation
Legacy Point Solutions
- Built over years, these tools now form a tangled web of dependencies
- They’re hard to scale, harder to replace, and increasingly expensive
- Overlapping capabilities create confusion and inefficiency
Code-Intensive Architectures
- Platforms demand specialized skills and deep technical expertise
- Business teams remain dependent on engineering for even basic data access
- Hadoop-era implementations failed to deliver promised flexibility
Part 3: The Cost of Complexity
Rising Software & Compute Costs
- Annual software license hikes (10–15%) are the new norm
- Cloud migrations often lead to sticker shock
- Tooling sprawl drives up operational overhead
Operational Overload
- Too many components to manage, monitor, and optimize
- Storage and compute maintenance becomes a full-time job
- Platform reliability suffers under the weight of complexity
Part 4: Agility Lost
- Building data products takes months, not days
- Business users wait in line for technical teams to deliver insights
- Platform selection and integration cycles are painfully slow
Even today, onboarding new data sources or replacing a BI tool feels like open-heart surgery. We’ve talked about modularity and service-oriented architecture for years — but few have achieved it.
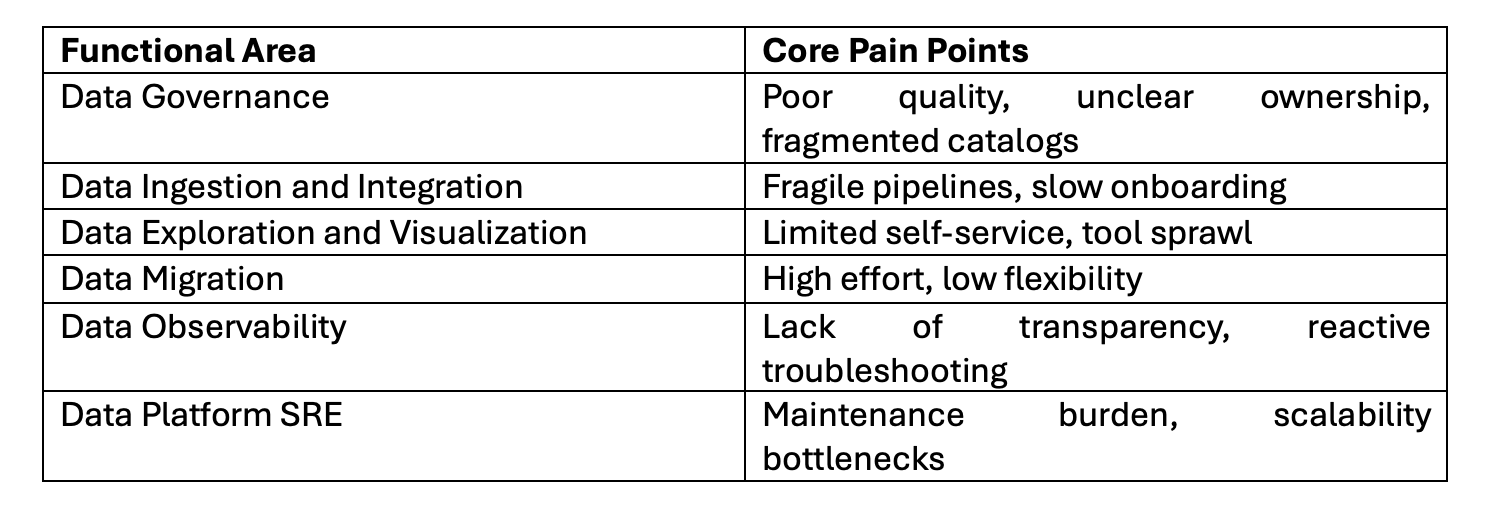
Part 5: Mapping the Problem Space
All these challenges can be grouped into six functional fault line
So where do we go from here?
There’s a seismic shift underway in the tech landscape — and data engineering is ripe for disruption. The AI coding tools market alone is projected to reach $20 billion by 2030, while broader IT services are expected to surge to $757 billion. The opportunity is massive.
AI-native platforms have the potential to transform data engineering end-to-end — from development and deployment to maintenance, support, and optimization. Startups that embrace this shift can help organizations slash budgets, automate complexity, and redefine scalability.
The future of data engineering isn’t just coming — it’s already here. And it will be powered by AI.