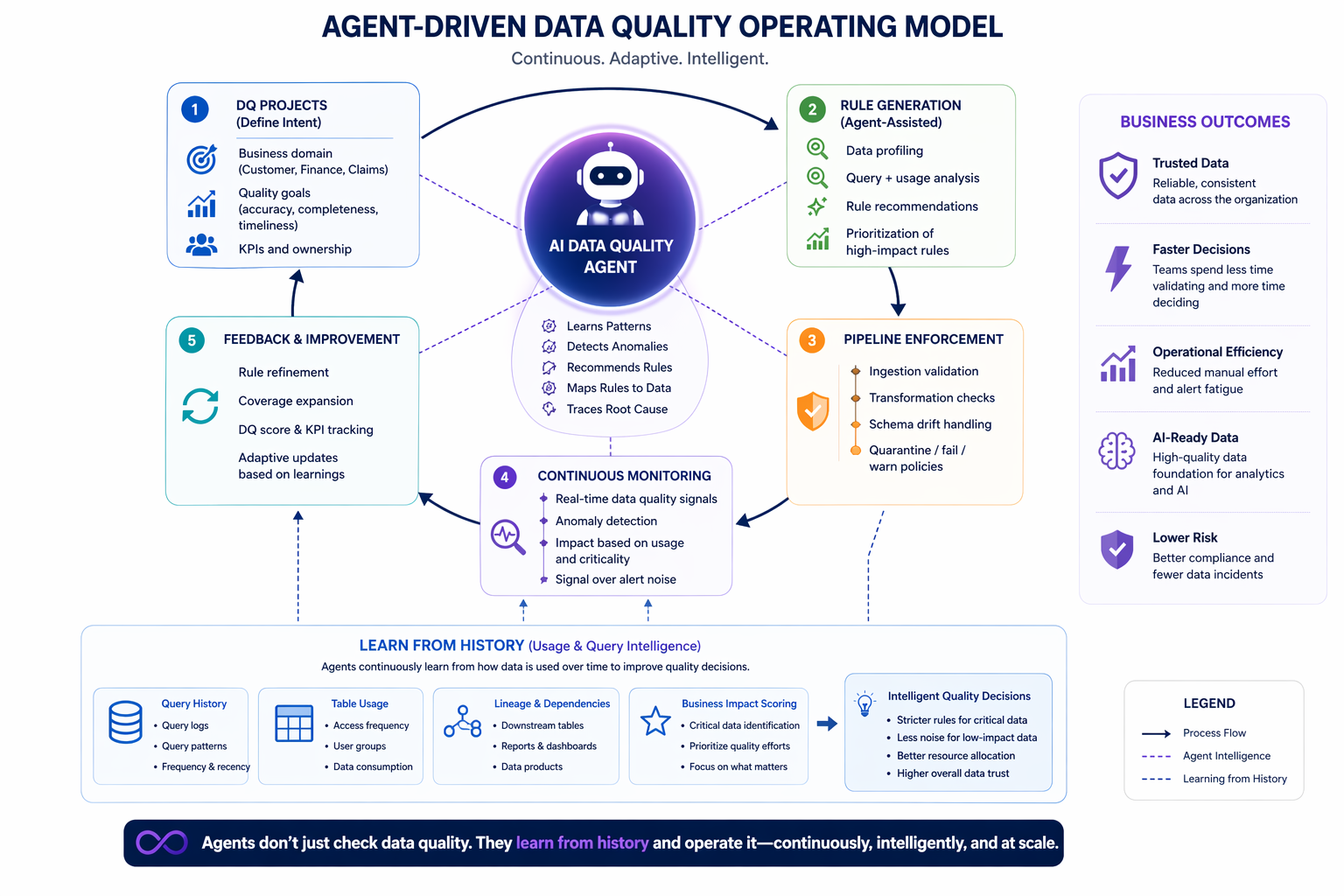
In my previous blog, I outlined a hard truth: despite decades of investment and countless migrations, the same recurring challenges continue to plague data engineering. Brittle pipelines, fragile delivery, bloated stacks, high costs, ever growing backlog of data requests from the business and the myth of a one-size-fits-all platform remain persistent blockers.
This naturally leads to the next question: what do enterprises need to build efficient, sustainable, and future-ready data and analytics platforms?
These blogs are my thoughts on the future of data engineering leverage AI from over 20 years of experience driving data and analytics transformation across global organizations. Most recently, I served as Head of Data Platforms & Engineering at Dun & Bradstreet, one of the world's oldest data companies, where I focused on the large-scale modernization of legacy systems, built exabyte-scale data platforms, and drove cloud migration and advanced analytics initiatives.
The Core Misstep: Tools ≠ Strategy
In recent years, organizations have flocked to the so-called “modern data stack.” Platforms like Snowflake, Databricks, etc., —combined with an array of shiny point solutions — were marketed as silver bullets. The promise was clear: agility, scalability, and democratization.
But here’s the uncomfortable reality: buying tools is not the same as building a enterprise data & analytics strategy.
Most enterprises now find themselves wrestling with overlapping capabilities across these point solutions, rising license costs, dedicated infra for these tools, need for dedicated specialized skilled resources for each point solution and fragile integrations. The outcome? A tangled web of dependencies that are hard to scale, harder to replace, and increasingly expensive to maintain. Business silos of data are complex & common.
Technology can enable transformation, but it cannot substitute for it.
A True Data Strategy Starts with the Business
The starting point isn’t technology. It’s asking the right questions:
- Which business levers must be pulled to accelerate results?
- Which teams need stronger decision support to execute better and faster?
- How can data be embedded directly into workflows, so insights translate into action?
A true data strategy is, first and foremost, a business transformation strategy. Technology choices should come after clarity on outcomes, not before.
Enterprise Must-Haves for a Future-Ready Data Platform
Across industries, I’ve seen the same core aspirations emerge. Enterprises don’t just want more tools; they want platforms that are simple, resilient, intelligent, and aligned with business outcomes.
Here are the six must-haves that map directly to the recurring fault lines I described earlier
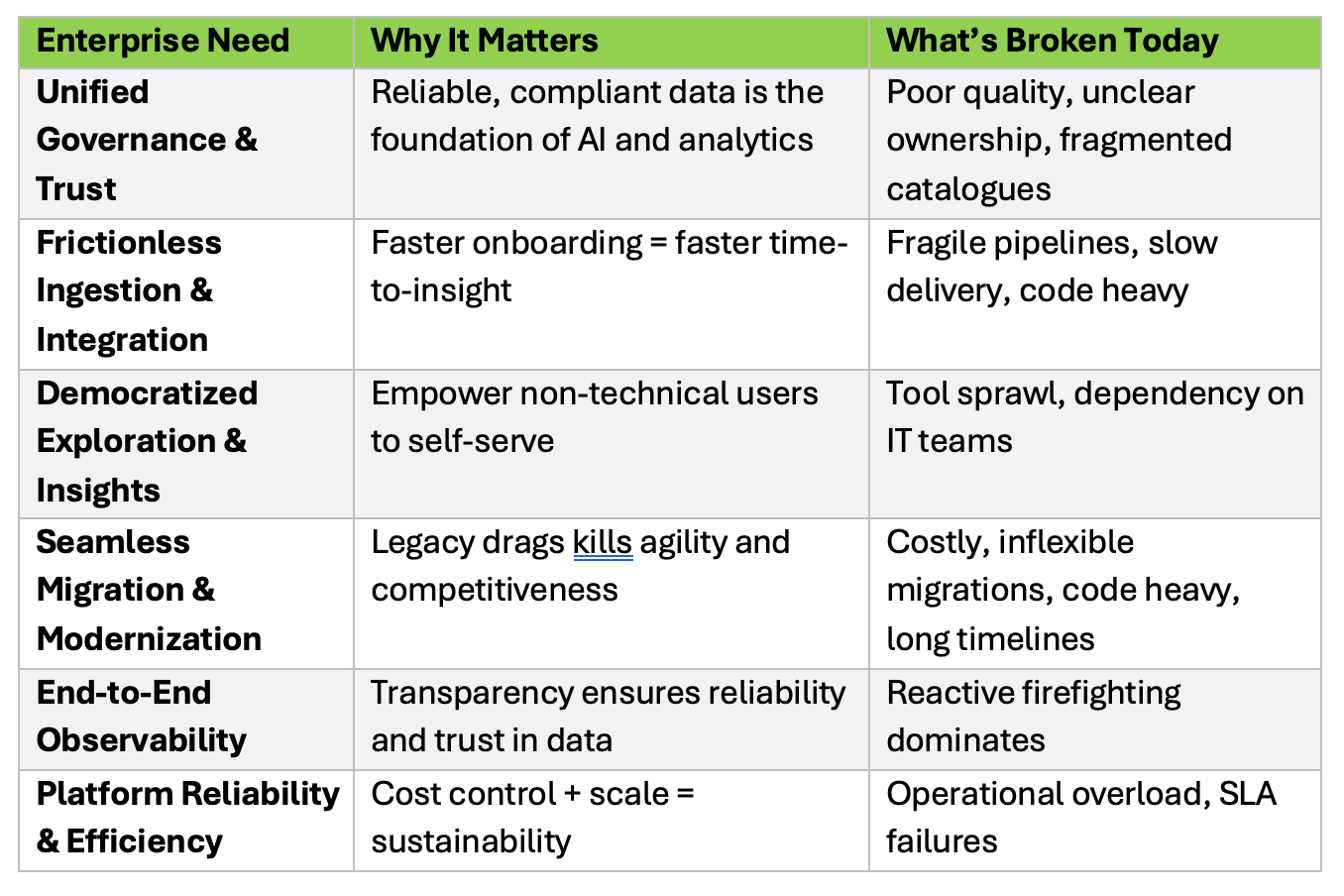
These needs aren’t about “keeping the lights on.” They’re about enabling agility, driving innovation, and ensuring every business function can move faster with confidence.
A part solution to these problems has been to onboard more data engineers, while this may fix the issue in the short term, it may result in more cost and complexity. There is also a danger of overlap between roles and responsibilities in the Data Team. Even with an expanded Data Team, the backlog of data request from the business starts to build up again. The business starts to develop shadow analytics and reporting to meet their needs and business requirements.
The AI Imperative
Today, the conversation around data platforms is inseparable from AI. Enterprises everywhere are racing to adopt GenAI. But here’s the catch:
No data strategy → No data foundation → No scalable AI.
AI-first organizations cannot exist without being data-first. And being data-first isn’t about collecting more platforms; it’s about building the foundation that makes AI sustainable, trustworthy, and impactful. Without fixing governance, ingestion, observability, and reliability, AI adoption risks becoming yet another expensive experiment.
The Future of AI in Data & Analytics Engineering
The future will not be owned by organizations that stockpile technology products. It will belong to those that synchronize data and AI strategy with business transformation.
Yet, the current trajectory of AI adoption in the enterprise is deeply flawed.
- AI itself is not failing—the failure lies in how it is being applied. Technology vendors are pouring billions into adding AI layers onto legacy point solutions, but this “bolt-on” approach does not reimagine the problem space. It is the equivalent of putting a modern jet engine on a horse-drawn carriage.
- Nearly every data product now claims to be “AI-powered.” But in truth, most are simply attaching an AI agent veneer on top of architectures that were never designed to be AI-native. These solutions are inherently limited, fragile, and unable to deliver the level of automation and intelligence that enterprises need.
- The interoperability problem is glaring. If every ETL, catalog, and observability tool has its own proprietary AI agent, how will these agents collaborate? Without a shared, AI-first foundation, enterprises will inherit a new wave of silos—this time with AI fragmentation replacing today’s data fragmentation.
Meanwhile, we have already witnessed the rise of AI agents across horizontal functions—HR, customer support, finance, and IT helpdesk. But the next wave of disruption will not be in these business processes. It will be in Data & Analytics Engineering itself.
For two decades, I have witnessed organizations struggle to scale data engineering: the endless coding, the integration of brittle tools, the delays in delivering products to market. With AI’s current maturity, we now stand at a turning point.
The next generation of enterprises will not rely on scattered point solutions but on a cohesive team of AI agents purpose-built for Data & Analytics Engineering where these agents will:
- Function as autonomous, always-available data engineers.
- Accelerate delivery by eliminating manual coding effort.
- Collaborate seamlessly across the data ecosystem as part of an orchestrated AI-native architecture.
- Drive outcomes at unprecedented speed and scale—freeing human teams to focus on innovation rather than repetitive engineering tasks.
This is not just a shift in tooling. It is a paradigm shift in how data related products are conceived, built, and delivered.
The winners in this new era will be those who build AI-native ecosystems, not AI-enhanced products. The transformation of Data & Analytics Engineering will not come from patching old tools with AI wrappers. It will come from reinventing the foundation itself—where AI is the architecture, not an accessory.
In my next blog, I’ll explore how to move from aspiration to execution—what AI-agent–driven data & analytics platforms could look like, and why the future of this field will be built on AI agents.