

Agents for Assurance: Elevating Data Quality Without the Heavy Lifting
There is a meeting that happens in almost every organization. It usually starts with a number a revenue figure that doesn't match last week's report, a customer count that differs across dashboards. Two analysts, same dataset, different answers. The meeting grinds to a halt. Trust evaporates. Instead of making the decision everyone came for, the next hour is spent debating which number is right.
This is the data quality problem. It is costing organizations more than they realize not just in time, but in delayed decisions, unreliable AI, engineering rework, and compliance risk.
Most organizations have already tried to fix this. Rules were written. Thresholds were set. Dashboards were built. Teams were assigned. For a while, it works. Then data grows, pipelines multiply, schemas evolve, and business logic changes faster than rules can keep up. Alerts increase. Teams start ignoring the noise. And quietly, data quality degrades again until the next meeting.
The problem is not effort. The problem is the model.
The Shift: From Monitoring to Operating
Traditional data quality systems are reactive, they detect issues after damage is done, remain static in the face of evolving data, and depend entirely on human effort to function. Modern data systems, by contrast, are continuous, dynamic, and distributed. That mismatch guarantees failure. Data quality cannot be monitored into reliability. It must be operated continuously by agents.
TRADITIONAL SYSTEMS ARE:
- Reactive: detect issues after damage is done
- Static: cannot adapt to evolving data
- Manual: depend on human effort
MODERN DATA SYSTEMS ARE:
- Continuous
- Dynamic
- Distributed
The diagram below illustrates what that operating model looks like in practice.
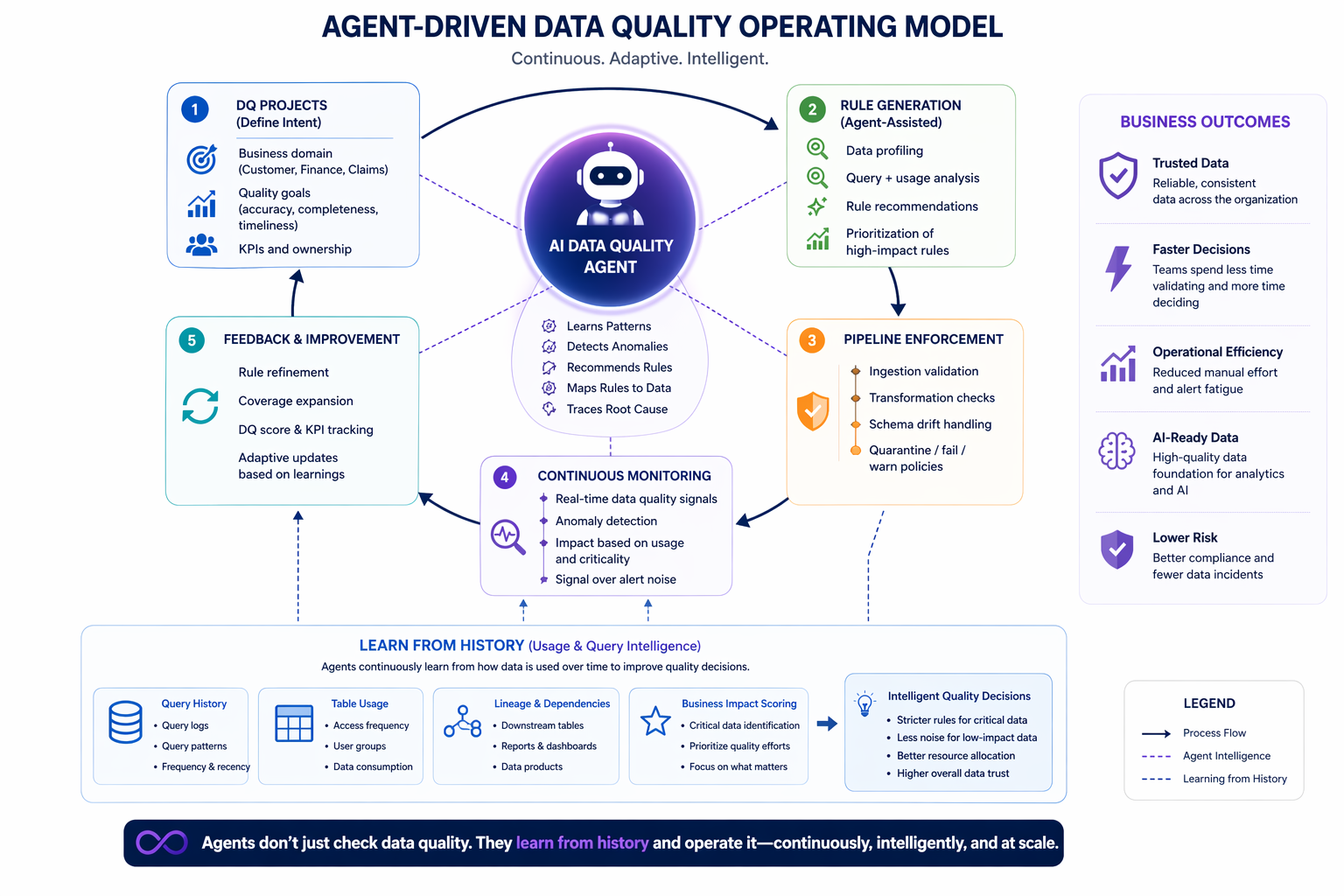
Agents don't just check data quality. They learn from history and operate it.
At its core is an AI Data Quality Agent operating across the full lifecycle from defining intent in DQ Projects, to generating and evolving rules, enforcing quality in pipelines, monitoring systems continuously and feeding improvements back into the loop. This is not a workflow. This is an operating model.
Learning From History and Acting on It
Traditional data quality systems look only at data. Agent-driven systems go further they learn from how data is actually used over time. The result is a fundamentally smarter approach: critical datasets receive stricter enforcement, low-impact datasets generate less noise and quality decisions align with actual business impact.
Data + Usage = Real Data Quality
- Query history: what queries are run, how often
- Table usage patterns: which datasets are criticalAccess frequency and recency
- Downstream dependencies: reports, dashboards, AI models
Not all data is equal. Agents learn what actually matters.
Adopting this model doesn't require a massive transformation, it requires a shift in how data quality is operated. That shift happens in five steps.
1. Define DQ Projects: Treat data quality as a structured execution model. Define domain scope, set quality goals around accuracy, completeness, and timeliness and establish KPIs and ownership. This makes quality measurable and accountable.
2. Generate Rules Intelligently: Move beyond manual rule creation. Use data profiling and query intelligence to focus effort on high-impact datasets. Humans guide. Agents scale.
3. Enforce Quality in Pipelines: Embed quality where data moves. Validate at ingestion, apply checks during transformation, handle schema drift explicitly, and prevent bad data from propagating downstream.
4. Replace Monitoring with Continuous Assurance: Dashboards don't fix problems. Agents do. Continuous signal tracking, reduced alert noise, and context-aware prioritization eliminate alert fatigue entirely.
5. Enable Continuous Improvement: Agents continuously refine rules, expand coverage, and adapt to new data patterns. Quality becomes a living, evolving system, not a static checklist.
Why This Changes Everything
When data quality is operated by agents, the effects ripple across the entire organization. Engineers spend less time fixing issues and more time building. Business users trust the data. Decisions move faster. AI systems become reliable.Data quality stops being a bottleneck and becomes a business enabler.
BigHammer is built for exactly this model. Data quality is not a separate tool, it is an embedded agent capability across the entire data lifecycle: ingestion, transformation, governance, and monitoring. What makes it powerful is the combination of agent-driven execution, pipeline-level enforcement, catalog intelligence and query and usage history learning. From data patterns to usage patterns to intelligent quality decisions.
Data quality became difficult when data systems outgrew human capacity to manage them. The solution isn't more dashboards or more rules. It's a different model, agent-driven data quality, powered by data and usage intelligence.
Data quality is no longer something you manage. It is something your system operates, continuously, intelligently and at scale.
Not monitored.
Not managed.
Operated.