Most organizations still treat data profiling as a checkbox exercise.
Generate a profile.
Export a report.
Store it somewhere nobody revisits.
But in the age of AI agents, profiling can no longer remain passive metadata.
At BigHammer, we believe profiling should become the intelligence layer that powers autonomous data operations.
Not just statistics.
Not just observability.
But grounded context that enables agents to understand how data behaves, evolves, breaks, and connects across the enterprise.
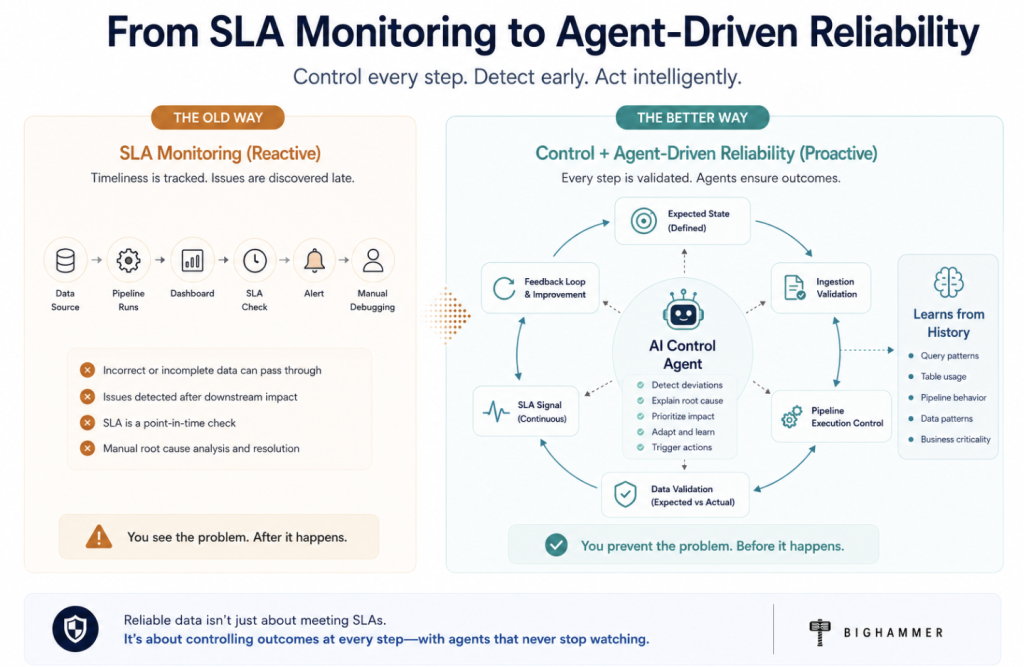
The Problem With Today’s AI Data Automation
Everyone wants AI-powered:
- pipeline generation
- data quality automation
- semantic exploration
- intelligent monitoring
- self-healing workflows
But most AI systems fail for one simple reason:
They do not actually understand the data.
An LLM can generate SQL.
It can recommend transformations.
It can suggest validations.
But without grounding in actual data behavior, the output becomes fragile:
- incorrect joins
- poor assumptions
- noisy alerts
- broken transformations
- hallucinated business logic
This is where profiling changes from a reporting feature into a foundational intelligence system.
Profiling Is No Longer Documentation
Traditional profiling focuses on:
- null counts
- distinct counts
- min/max values
- distributions
- duplicate percentages
Useful? Yes.
Sufficient for intelligent automation? Not even close.
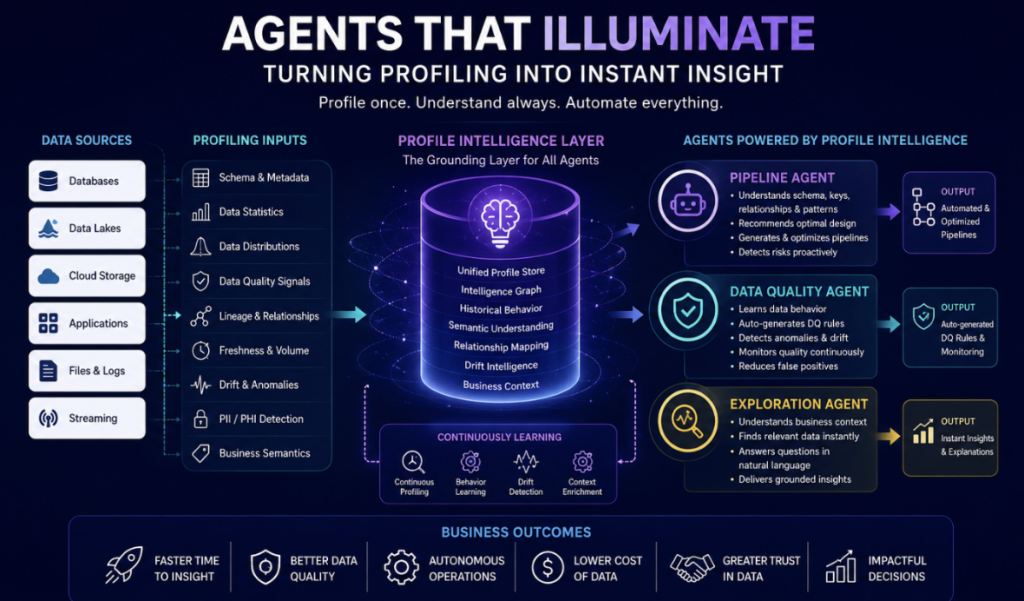
BigHammer transforms profiling into a continuously evolving Profile Intelligence Layer.
This layer captures:
- schema behavior
- historical drift
- semantic inference
- lineage awareness
- PII/PHI classification
- relationship discovery
- freshness patterns
- anomaly signatures
- distribution evolution
- operational metadata
- transformation lineage
- business context
The result is a living understanding of enterprise data.
The Rise of Grounded Data Agents
AI agents become powerful only when grounded in trusted operational context.
BigHammer uses profiling intelligence to power multiple autonomous agents across the platform.
Instead of isolated features, profiling becomes shared intelligence for the entire ecosystem.
1. Pipeline Agents That Understand Data
Imagine a user says:
“Create an incremental customer claims pipeline from Snowflake into Delta Lake.”
A traditional AI assistant might generate generic SQL.
But a grounded Pipeline Agent understands:
- which columns behave like primary keys
- which timestamp is suitable for CDC
- whether late-arriving data exists
- historical volume patterns
- schema evolution history
- sensitive columns requiring masking
- join cardinality behavior
- partition optimization opportunities
The result is not just generated code.
It is context-aware pipeline automation.
The agent can proactively:
- recommend partitioning
- suggest merge strategies
- detect skew risks
- optimize transformations
- identify unstable schemas
- recommend lineage-aware retries
Profiling becomes operational intelligence.
2. Data Quality Agents That Learn Automatically
Most DQ systems still depend on manually written rules.
That approach does not scale.
BigHammer’s profiling intelligence allows DQ Agents to infer rules directly from observed data behavior.
For example:
- claim_amount historically ranges between 0–25,000
- null percentage stays below 0.1%
- daily volume averages 2 million records
- diagnosis codes follow known patterns
- member IDs maintain uniqueness
- claims arrive within expected SLA windows
Using this intelligence, agents can automatically generate:
- range checks
- drift detection
- freshness monitoring
- schema evolution alerts
- volume anomaly detection
- duplicate detection
- referential integrity validations
- distribution change monitoring
Without requiring users to manually define every rule.
This changes data quality from reactive governance into autonomous prevention.
3. Exploration Agents That Understand Business Context
Business users should not need to understand table structures before asking questions.
But generic AI exploration tools often lack grounding in enterprise semantics.
A user asks:
“Why did denied claims increase last week?”
A grounded Exploration Agent can already understand:
- relevant claims datasets
- historical denial trends
- recent schema changes
- upstream ingestion failures
- distribution shifts
- payer-specific anomalies
- related operational incidents
Instead of returning disconnected charts, the agent delivers explainable insight with context.
This is the difference between:
querying data
and
understanding data.
From Profiling to a Profile Intelligence Graph
At BigHammer, profiling is not a standalone report.
It becomes a continuously evolving intelligence graph connecting:
- datasets
- pipelines
- quality signals
- lineage
- semantics
- operational telemetry
- business entities
- transformation history
This graph becomes the grounding system for every AI-driven capability in the platform.
The same intelligence can power:
- orchestration
- observability
- quality
- recommendations
- cost optimization
- governance
- root-cause analysis
- self-healing pipelines
Build context once. Reuse everywhere.
Why This Matters
Enterprise data platforms are becoming increasingly autonomous.
But autonomy without grounding creates risk.
The future belongs to platforms where agents:
- understand the data
- learn continuously
- adapt to drift
- explain decisions
- operate with lineage awareness
- generate trustworthy automation
Profiling is no longer a passive activity.
It becomes the cognitive layer of the modern data platform.
The Bigger Shift
We are moving from:
- dashboards → decisions
- metadata → intelligence
- pipelines → autonomous operations
- rule engines → adaptive systems
- AI assistants → grounded agents
And profiling sits at the center of this transformation.
At BigHammer, we believe the next generation of data platforms will not just process data.
They will understand it.
And the foundation of that future is Profile Intelligence.