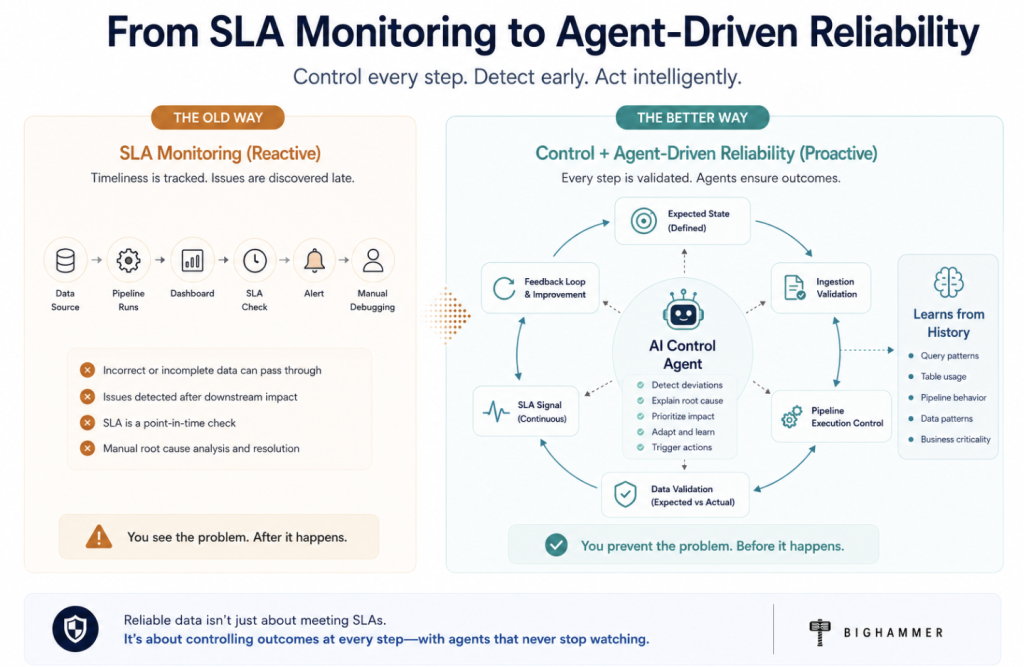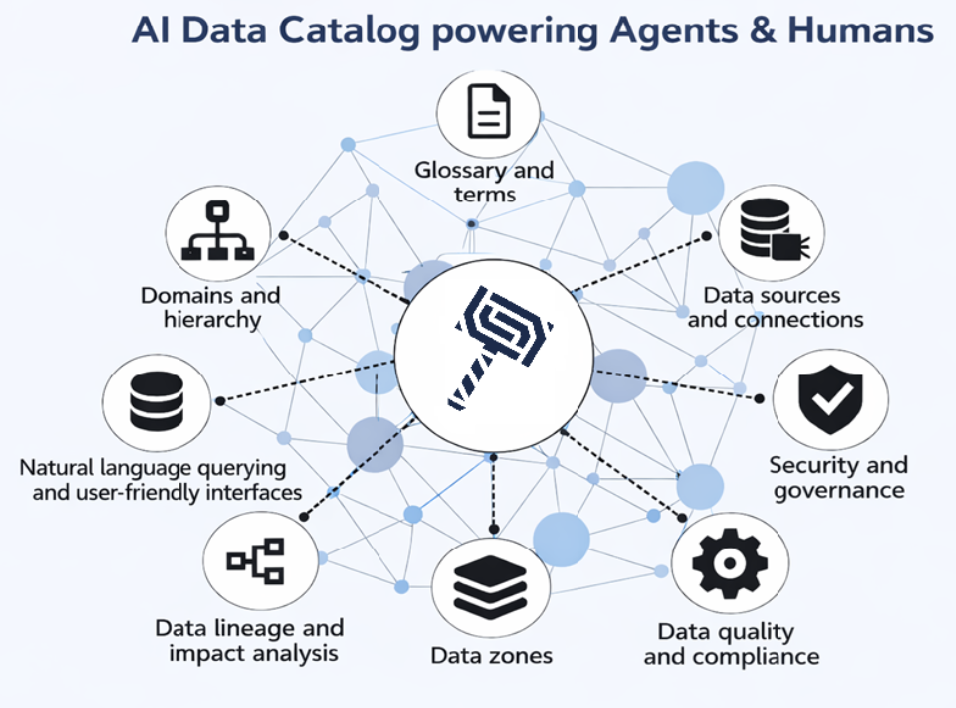
Most enterprises already know what a data catalog is supposed to hold: where datasets live, who owns them, how they connect, and whether they’re fit for analytics or regulated workloads. The harder question is whether that knowledge stays accurate once automation and AI enter the picture and whether systems can act on it without waiting for a human.
At BigHammer, the catalog is not a static handbook. It’s shared infrastructure for both people and machines, continuously updated, API-first, and designed to power agents that govern, discover, and build pipelines without manual intervention.
Why BigHammer is different?
What makes BigHammer different is not just that the catalog is “live” it is the single control plane for metadata, execution, and agents. The same schema that defines assets is used to drive UI behaviour, pipeline execution and agent decisions. There is no translation layer between documentation and runtime systems.
Unlike traditional catalogs or even modern metadata platforms, BigHammer unifies:
- design-time intent (schemas, mappings, policies)
- runtime behavior (queries, pipeline execution, lineage)
- agent actions (governance, quality, onboarding)
This convergence is what allows automation to operate safely without drift.
Why traditional catalogs stall
Legacy catalogs were built for occasional human lookups. Metadata was entered by hand, refreshed on schedules, and scattered across tools that didn’t share the same view of your data. Teams struggled to find the right table. Definitions drifted from reality. Automation quietly broke because the catalog never kept pace with the warehouse.
AI workloads expose this limitation immediately. Models and agents require structured, real-time, machine-readable context, not delayed metadata or human-maintained glossaries.
Most catalogs fail not because they lack metadata, but because they are not connected to execution. As a result, automation operates on stale context, and trust breaks down.
What a living catalog has to do
A catalog built for modern data work has to hold several things together at once: unified context across business domains, technical assets and their relationships; discovery that serves both analysts typing keywords and agents making API calls; lineage that traces data to the field level, not just the table; governance signals sensitivity, ownership, quality thresholds embedded where automation can read them; and enterprise-grade security that isolates each organisation’s data from day one.
When these come together in a single metadata graph, the catalog stops being a reference document and becomes operating infrastructure.
In BigHammer, this is implemented as a unified metadata graph backed by versioned schemas and event-driven updates. Changes from ingestion, transformation, or query execution continuously update the graph, ensuring that both humans and agents operate on the same state.
How BigHammer structures it
The BigHammer catalog is organised around a handful of first-class concepts that map to real decisions and real accountability.
Domains give data a home. They’re hierarchical, owned, and carry structured context business rules, quality expectations and institutional knowledge that would otherwise live only in someone’s head. Every asset in the catalog belongs to a domain with a named steward.
Glossary terms give data a shared language. Terms are versioned and lifecycle-managed drafted, reviewed, approved, deprecated and linked directly to the datasets that implement them. Synonyms and semantic search mean you can find an asset by what it means, not just what it’s called. Sensitivity labels like PII and PHI travel with the term, so policy is visible precisely where it needs to be enforced.
Data sources are where everything physical meets the catalog. Whether your data lives in a cloud warehouse, a relational database, a file store, or any other system, BigHammer registers it in one place as a source, a target, or both. Each asset carries provenance: who connected it, which domain it belongs to, and which glossary terms govern it. Nothing falls outside the graph.
For example, when a new data source is onboarded:
- the Onboard Agent registers the connection
- schema and statistics are inferred automatically
- domain and glossary mappings are suggested
- sensitivity tags (PII/PHI) are applied at field level
- lineage is initialized
- pipelines can be generated or updated
All of this happens without manual catalog entry and every step is auditable.
Zones reflect the maturity of your data, not just its location. Following the medallion pattern raw, cleansed, curated zones let the catalog communicate trust level at a glance. A dataset in the raw layer and one in the curated layer are fundamentally different things, and BigHammer makes that distinction visible to every person and system that touches them.
Lineage is a continuous record of the full data journey: from connection to data source to pipeline to transformation, down to individual fields. When a query runs, BigHammer ties it back to the catalog objects it touched. Design-time lineage captures intent; runtime lineage captures what actually happened. Unlike systems that capture lineage only at design time or only from query logs, BigHammer reconciles both. This allows teams to detect drift between intended transformations and actual execution.
Flows and pipelines close the loop between metadata and execution. BigHammer maintains versioned, declarative pipeline and flow definitions—validated through shared schemas across the UI, the catalog, and the agent layer that run as governed, auditable jobs. The catalog doesn’t just describe what data does; it participates in doing it.
The agent layer
When the catalog is continuously updated and API-first, agents become a natural extension of governance and discovery rather than a bolt-on feature. BigHammer ships a family of agents, each scoped to a specific job:
- Pipeline Agents: align transformations and mappings with the latest metadata.
- Ops Agents: monitor operational health and reconcile catalog changes with runtime environments.
- Data Quality Agents: enforce rules, track anomalies, and surface trust signals directly in the catalog.
- Governance Agents: apply sensitivity tags, ownership rules, and compliance policies where automation touches.
- Data Explorer Agents: help analysts and AI models discover assets with semantic context, not just keywords.
- Onboard Agent: connects new data sources to the catalog automatically, registering connections, inferring domain and glossary mappings, and populating metadata without manual entry.
Finding data should not require knowing the catalog
Most catalogs reward people who already know what they’re looking for. BigHammer is built around the opposite idea: you should be able to describe what you need and get a meaningful answer.
The Data Explorer Agent lets analysts ask questions in plain language and get back results anchored to real catalog assets with domain, ownership, and sensitivity context already attached. The Onboard Agent can infer domain mappings and glossary matches from a description, so cataloguing a new source doesn’t start from a blank form.
The bottleneck in most data organisations isn’t compute or storage, it’s the cost of finding, understanding, and trusting data. Lowering that cost through language-driven discovery, backed by a reliable metadata graph, is what makes the catalog useful to people who aren’t data engineers.
Takeaways
- Most enterprise data goes underused because finding, understanding, and trusting it is too expensive, not because it lacks value.
- A catalog designed for AI needs to be continuously updated, API-first, and connected to execution, not just documentation.
- Domains, glossary, lineage, zones, sensitivity, and pipelines belong in one coherent layer, not separate tools.
- Agents that share the same metadata graph can govern, discover, and build and they earn trust because they’re working from the same source of truth as everyone else.
BigHammer’s direction is deliberate: treat the catalog as the control plane for the entire data system. By unifying metadata, execution, and agent-driven automation, it removes the fragmentation that slows down modern data teams.
In an AI-native stack, the catalog is no longer a reference layer, it is the system that everything else depends on.